在看过了上面的几节之后,在潜意识中你想记住的东西肯定很多了。这个时候,你需要静下心来休息一下在沉淀一下。
"Now is a good point to take a break to let this information sink in."
下面,我们就看看C语言撰写的程序,在不同的CPU架构下,生成的汇编语言是怎么样的,各有什么特点,这和前面介绍的各种CPU架构的知识是如何联系的。如果你觉得还不够,也很高兴一起来探讨一下在不同的CPU架构下,函数的调用时如何实现的,以及各有什么特点。
反汇编文件
测试用的C源码如下,main.c文件:
#include <stdio.h>
int add(int a,int b)
{
return a+b;
}
int main(int argc,char** argv)
{
int a,b,c;
a = 1;
b = 2;
c = fn(a,b);
return c;
}
下面为编译以及反汇编的过程。当然,ARM和MIPS的编译和反汇编是使用的交叉编译工具链。例如在我的平台下,对应的命令就是ccarm,objdumparm和ccmips,objdumpmips。
#gcc -o main.o -c main.c #objdump -d main.o>main.a
编译成x86下面的main.o文件,注意,没有链接。然后反汇编为main_x86.a如下所示。这里需要指出的是,下面的汇编语言并不是我们在《微机原理》课本上学习到的x86的汇编(我们称为intel汇编),而叫做AT&T汇编。那么,什么是AT&T汇编呢?
在将Unix移植到80386处理器上时,Unix圈内人士根据Unix领域的习惯和需要而定义了AT&T汇编。而GNU主要是在Unix领域活动,因此GNU开发的各种系统工具继承了AT&T的386汇编格式,这也是我们使用GNU工具进行反汇编的时候,看到的汇编语言。
main.o: file format elf32-i386 Disassembly of section .text: 00000000 <add>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 8b 55 0c mov 0xc(%ebp),%edx 6: 8b 45 08 mov 0x8(%ebp),%eax 9: 01 d0 add %edx,%eax b: 5d pop %ebp c: c3 ret 0000000d <main>: d: 8d 4c 24 04 lea 0x4(%esp),%ecx 11: 83 e4 f0 and $0xfffffff0,%esp 14: ff 71 fc pushl -0x4(%ecx) 17: 55 push %ebp 18: 89 e5 mov %esp,%ebp 1a: 51 push %ecx 1b: 83 ec 24 sub $0x24,%esp 1e: c7 45 f0 01 00 00 00 movl $0x1,-0x10(%ebp) 25: c7 45 f4 02 00 00 00 movl $0x2,-0xc(%ebp) 2c: 8b 45 f4 mov -0xc(%ebp),%eax 2f: 89 44 24 04 mov %eax,0x4(%esp) 33: 8b 45 f0 mov -0x10(%ebp),%eax 36: 89 04 24 mov %eax,(%esp) 39: e8 fc ff ff ff call 3a <main+0x2d> 3e: 89 45 f8 mov %eax,-0x8(%ebp) 41: 8b 45 f8 mov -0x8(%ebp),%eax 44: 83 c4 24 add $0x24,%esp 47: 59 pop %ecx 48: 5d pop %ebp 49: 8d 61 fc lea -0x4(%ecx),%esp 4c: c3 ret
编译成mips下面的main.o文件,没有链接。然后反汇编为main_mips.a:
main.o: file format elf32-bigmips Disassembly of section .text: 0000000000000000 <add>: 0: 27bdfff8 addiu $sp,$sp,-8 4: afbe0000 sw $s8,0($sp) 8: 03a0f021 move $s8,$sp c: afc40008 sw $a0,8($s8) 10: afc5000c sw $a1,12($s8) 14: 8fc20008 lw $v0,8($s8) 18: 8fc3000c lw $v1,12($s8) 1c: 00000000 nop 20: 00431021 addu $v0,$v0,$v1 24: 03c0e821 move $sp,$s8 28: 8fbe0000 lw $s8,0($sp) 2c: 03e00008 jr $ra 30: 27bd0008 addiu $sp,$sp,8 0000000000000034 <main>: 34: 27bdffd8 addiu $sp,$sp,-40 38: afbf0024 sw $ra,36($sp) 3c: afbe0020 sw $s8,32($sp) 40: 03a0f021 move $s8,$sp 44: afc40028 sw $a0,40($s8) 48: afc5002c sw $a1,44($s8) 4c: 24020001 li $v0,1 50: afc20010 sw $v0,16($s8) 54: 24020002 li $v0,2 58: afc20014 sw $v0,20($s8) 5c: 8fc40010 lw $a0,16($s8) 60: 8fc50014 lw $a1,20($s8) 64: 0c000000 jal 0 <add> 68: 00000000 nop 6c: afc20018 sw $v0,24($s8) 70: 8fc20018 lw $v0,24($s8) 74: 03c0e821 move $sp,$s8 78: 8fbf0024 lw $ra,36($sp) 7c: 8fbe0020 lw $s8,32($sp) 80: 03e00008 jr $ra 84: 27bd0028 addiu $sp,$sp,40 ...
编译成arm下的main.o,没有链接。然后反汇编为main_arm.a:
main.o: file format elf32-littlearm
Disassembly of section .text:
00000000 <add>:
0: e1a0c00d mov r12, sp
4: e92dd800 stmdb sp!, {r11, r12, lr, pc}
8: e24cb004 sub r11, r12, #4 ; 0x4
c: e24dd008 sub sp, sp, #8 ; 0x8
10: e50b0010 str r0, [r11, -#16]
14: e50b1014 str r1, [r11, -#20]
18: e51b3010 ldr r3, [r11, -#16]
1c: e51b2014 ldr r2, [r11, -#20]
20: e0833002 add r3, r3, r2
24: e1a00003 mov r0, r3
28: ea000009 b 2c <add+0x2c>
2c: e91ba800 ldmdb r11, {r11, sp, pc}
00000030 <main>:
30: e1a0c00d mov r12, sp
34: e92dd800 stmdb sp!, {r11, r12, lr, pc}
38: e24cb004 sub r11, r12, #4 ; 0x4
3c: e24dd014 sub sp, sp, #20 ; 0x14
40: e50b0010 str r0, [r11, -#16]
44: e50b1014 str r1, [r11, -#20]
48: e3a03001 mov r3, #1 ; 0x1
4c: e50b3018 str r3, [r11, -#24]
50: e3a03002 mov r3, #2 ; 0x2
54: e50b301c str r3, [r11, -#28]
58: e51b0018 ldr r0, [r11, -#24]
5c: e51b101c ldr r1, [r11, -#28]
60: ebfffffe bl 0 <add>
64: e1a03000 mov r3, r0
68: e50b3020 str r3, [r11, -#32]
6c: e51b3020 ldr r3, [r11, -#32]
70: e1a00003 mov r0, r3
74: ea00001c b 78 <main+0x48>
78: e91ba800 ldmdb r11, {r11, sp, pc}
不同CPU架构下汇编语言的特点
代码长度
首先,我们看同一个C语言程序,在不同的处理器下,代码长度。代码长度为反汇编文件的第一列,可以看到,在x86下是0x4c+1个字节,在MIPS下是0x84+4个字节,在ARM下是0x78+4个字节。为什么这样呢?
首先看的是CISC和RISC的区别 CISC架构下,指令的长度不是固定的,而RISC为了实现流水线,每条指令的长度都是固定的。看到反汇编文件的第二列,x86的指令中,最短为一个字节,例如push,pop,ret等指令,最长为7个字节,例如movl指令。而对于ARM和MIPS,所有的指令长度都固定为4个字节。这也是ARM和MIPS的机器代码长度要明显比x86长的原因。
另外一个原因,就是CISC可能为某个特殊操作实现了一条指令,而RISC处理器则需要用多条指令组合来完成该操作。最明显的就是出入栈操作。
然后我们看MIPS和ARM的区别 ARM的代码长度比MIPS代码长度稍稍小,这也验证了人们常说的MIPS是纯粹的RISC架构,而ARM则在RISC的基础上吸收了CISC中的某些优点。我们还是要看看,ARM是因为吸收了哪些CISC的特点,才做到代码长度的减少的呢?最明显的是出入栈,在ARM中实现了多寄存器load/store指令,请注意main_arm.a文件的0x4,0x2c,0x34,0x78行的stmdb和ldmdb指令。那么,这和CISC有什么关系呢?仔细想想,这就是CISC中的为了某个特殊的操作而实现一条指令的思想。另外,多寄存器的load/store指令破坏了RISC中指令的执行周期必须是单周期的规定,这一点,也是人们指责ARM不是纯粹的RISC架构的证据之一。
另外还有就是ARM实现了条件标志,实现条件执行,这样可以减少分支指令的数目,提高代码的密度。不过在我们这个实例中没有这方面的应用。
出栈入栈
入栈指将CPU通用寄存器的值放入栈(存储器)中保存起来。出栈则是指将栈中的值恢复到CPU中相应通用寄存器。
在x86下面,有专门的出栈和入栈指令pop和push。出栈和入栈在栈中的位置是当前堆栈指针sp所指向的位置。在MIPS和ARM下面,没有专门的指令,所以入栈和出栈首先使用的是load/store指令将数据放入堆栈或者弹出堆栈,然后使用add/stub指令修改堆栈指针的值。比较特殊的是ARM有特殊的多寄存器load/store指令来快速的完成出入栈。由此可见,在MIPS和ARM下面,出入栈都是使用帧指针或者堆栈指针的相对位置,在执行之后,并不会影响堆栈指针sp的值。
栈的生长 栈的生长指堆栈指针sp的变化。例如,在函数调用的时候,需要一次性的分配被调用函数的栈空间大小。在x86,ARM,MIPS下都是使用的对堆栈指针寄存器直接加减的办法。而且,在MIPS和ARM下,也只有这种办法可以改变堆栈指针SP的值。而在x86下,除了直接加减的办法之外,出入栈操作指令pop和push还可以改变sp的值。
不同CPU架构下函数调用的特点
C语言函数的调用,请参考C语言-Stack的相关内容。涉及堆栈帧(stack frame),活动记录(active record),调用惯例(call convention)等相关概念。建议参考《程序员的自我修养-链接、装载与库》的第10.2节-栈和调用惯例。
毫无疑问,这里都是使用的C语言的默认调用惯例cdecl。cdecl调用管理的特点如下:
- 调用的出栈方为函数调用方;
- 参数的传递为从右向左入栈;
- 名字修饰为下划线+函数名;
首先我们给出一个cdecl调用惯例的模型,不针对任何处理器架构,然后我们再看看不同的处理器架构下cdecl调用惯例有什么样的特点。下图为cdecl调用惯例的一般情况示意图。
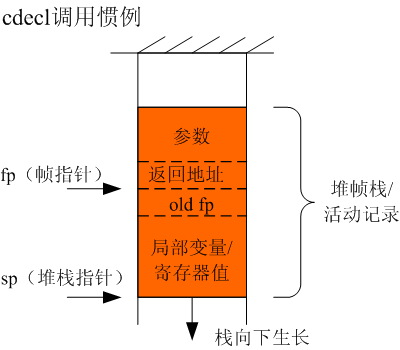
下面分析cdecl调用惯例中,调用函数和被调用函数分别负责活动记录(堆帧栈)中的什么操作呢?首先是被调用函数,在函数的入口,需要做以下操作:
-
需要将返回地址入栈,例如MIPS下的
sw \(ra,28(\)sp)一句,就是将函数的返回地址入栈。对于x86架构,由于call命令会自动将返回地址入栈,所以在函数入口处没有返回地址入栈的指令; -
需要将调用函数的帧指针入栈,然后设置本身自己函数的帧指针。在x86下,是
push %ebp;mov %esp,%ebp两句,而在MIPS下,是sw \(s8,24(\)sp);move \(s8,\)sp;两句。这里也可以看出x86的拥有专门入栈指令的特点push的特点; - 调整堆栈指针的大小,升栈到函数需要的堆栈大小。
上面是被调用函数需要负责的事情,那么调用函数需要负责什么呢?主要有一下几点:
- 准备好函数调用参数;
- 调用指令call跳转到被调用函数。
X86的函数调用
这个调用中没有调整堆栈指针的操作,因为不需要用到额外的堆栈空间。所以,只有上面提到的第一点和第二点。
push %ebp mov %esp,%ebp ...... pop %ebp ret
MIPS的函数调用
MIPS的堆栈,在被调用函数中有8bytes的升栈操作,下面的ARM中也是一样的。
addiu $sp,$sp,-8 sw $s8,0($sp) move $s8,$sp ...... move $sp,$s8 lw $s8,0($sp) jr $ra addiu $sp,$sp,8
ARM的函数调用
相比于MIPS架构,一条stmdb和ldmdb就可以完成多个寄存器的存储(store)和加载(load)。
mov r12, sp
stmdb sp!, {r11, r12, lr, pc}
sub r11, r12, #4 ; 0x4
sub sp, sp, #8 ; 0x8
......
b 2c <add+0x2c>
ldmdb r11, {r11, sp, pc}
轻松一下
我们可以用《盗梦空间》来形容函数调用和堆栈操作。现实与梦,梦中有梦,层层深入。梦的层数太多,以至于不知道自己位于第几层梦境,以至于回到了现实还以为自己在做梦……
海报

海报-男主角

海报-最终没有回到现实的女主角

- 2012.1.16 终于完成函数调用部分内容,虽然还很粗糙;